
:quality(70)/cloudfront-eu-central-1.images.arcpublishing.com/irishtimes/YG66U2GBZFHNBO7ZWJ46NZAEGU.jpg)



Нейронная сеть LSTM использовалась для прогнозирования базового эффективного коэффициента умножения BEAVRS. КвлияниеДля подготовки модели прогнозирования были взяты различные параметры бифуркации.17,18,19,20Конкретный метод работы показан на рисунке 5.
Базовая блок-схема эффективного умножения на основе LSTM Квлияние Метод прогнозирования.
Предварительная обработка данных
Эффективный коэффициент умножения Квлияние Он рассчитывался DRAGON/DONJON за период 0–300 дней при максимальной мощности с частотой выборки 1 день. Из-за большой разницы в диапазоне значений разных величин признаков проводится линейная нормализация.17 Этот метод (т. е. метод максимальной нормализации) используется для нормализации больших количеств признаков для достижения большей точности модели. Формула появляется в уравнении. (6), где с Это начальное значение функции Квлияние, свыше является абсолютным преимуществом, сминута это минимальная функция, и с* значение обрабатываемого признака20.
$$ x^{*} = \frac{{x — x_{\min } }}{{x_{\max } — x_{\min } }} $$
(6)
Модельное обучение
В этом исследовании функция потерь, используемая для обучения модели, представляет собой среднеквадратическую ошибку (MSE), которая представляет собой отношение квадрата разницы между ожидаемыми и фактическими значениями к количеству выборок. Пусть размер выборки равен n, ожидаемое эффективное значение k равно y*, а фактическое эффективное значение k равно y. Формула MSE приведена в уравнении. (7) Из чего можно сделать вывод, что чем меньше MSE, тем меньше ошибка и тем больше эффект прогнозирования. Точность модели определяется путем сравнения абсолютной ошибки (y* — y) прогнозируемого эффективного значения k с фактическим значением.
$$ MSE = \frac{1}{n}\sum\limits_{i = 1}^{n} {\left( {y_{i}^{*} — y_{i} } \right)^{2 } } $$
(7)
В обучающем наборе формируется модель прогнозирования с использованием обработанных данных и настроек гиперпараметров, показанных в таблице 3. Обученная модель используется для тестирования тестового набора в соответствии с процессами, описанными ниже: На основе обучающего набора временные шаги коллективно определяется в порядке от 1 до 10 (интервал 1) В зависимости от производительности используемого компьютера количество нейронов, скрытых в слое LSTM [4, 8, 16, 32]коэффициент регуляризации модели 0,001–0,01 (интервал 0,001), оптимизатор Коэффициенты регуляризации модели 0,001–0,01 (интервал 0,001), выбраны оптимизаторы [adam, RMSProp, Adagrad, Adadelta]а также указывается соответствующее количество периодов итераций, размер пакета, вызовы функций обратного вызова и частота отсева.
Коэффициент регуляризации L2 используется вместе со слоем исключения, чтобы уменьшить переобучение модели. На основе бритвы Оккама21, если чему-либо есть два объяснения, то наиболее вероятным истинным будет объяснение с наименьшим количеством предположений, т. е. наиболее прямой ответ. Учитывая некоторые данные обучения и дизайн сети, данные можно интерпретировать с помощью нескольких взвешенных значений (т. е. нескольких моделей). Сложные модели более склонны к переоснащению, чем простые модели. Простые модели – это модели с меньшим количеством параметров. Уменьшая сложность модели путем ограничения весов модели меньшими значениями, распределение значений весов становится более равномерным. Этот метод называется регуляризацией веса, которая достигается путем добавления стоимости, связанной с большими значениями веса, к функции потерь сети и добавления коэффициента регуляризации L2, т.е. дополнительные затраты пропорциональны квадрату весового модуля. (норма весов L2), как показано в уравнении. (8), где ẫ Она преподаватель-организатор. ЧАСв – ошибка обучающей выборки без коэффициента регулирования, к Это функция потерь. Феллс22 Относится к процессу обучения глубокому обучению. Для модуля обучения нейронной сети он удаляется из сети на основе определенной вероятности в целях случайного градиентного спуска. На рисунке 6 изображен рабочий процесс, который предотвращает переобучение модели путем случайного удаления нейронов.
$$ L = E_{{{\text{in}}}} + \lambda \sum\limits_{j} {w_{j}^{2} } $$
(8)
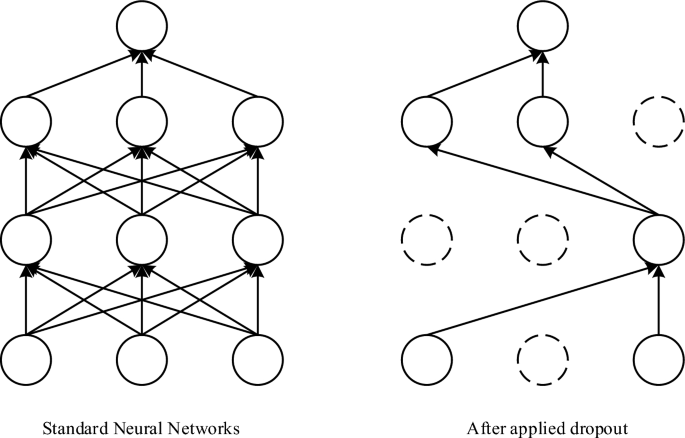
Схема механизма утечки.
В машинном обучении многие методы оптимизации23,24 Они используются для поиска наилучшего модельного решения. В отличие от RMSProp, где отсутствие поправочных коэффициентов может привести к сильно смещенным оценкам квадратичных моментов в начале обучения, Адам содержит смещенные поправки, которые представляют моменты первого порядка (члены импульса), инициализированные из исходного и (децентрализованного) квадратичного момента. оценки .
Анализ результатов
Временные шаги алгоритма LSTM установлены в пределах 1–10; Число нервных единиц было 4, 8, 16 и 32; Коэффициенты регуляризации составляли 0,001–0,01, а оптимизаторы были adam, RMSProp, Adagrad и Adadelta соответственно для моделирования первых 65% набора данных и построения в общей сложности 1600 моделей алгоритмов LSTM для следующих 35% набора данных для прогнозирования и ошибки сравнения.Абсолютная ошибка между прогнозируемыми и истинными значениями используется в качестве индикатора для оценки.Результаты показаны на рисунке 7.
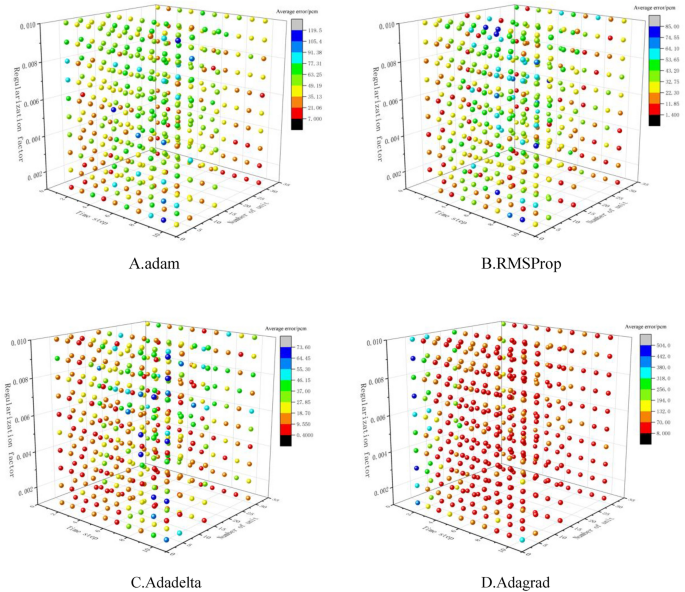
Из рис. 7 видно, что для основной задачи эффективного оператора умножения Квлияние, модель алгоритма LSTM, основанная на Adadelta, имеет лучший прогноз, за ней следуют RMSProp и adam, а Adagrad имеет худший прогноз; Для оптимизаторов RMSProp, Adagrad и Adadelta средняя ошибка увеличивается, а затем уменьшается по мере увеличения коэффициента регуляризации. Средняя ошибка увеличивается, а затем уменьшается, затем увеличивается у Мухсина Адама, а у Мухсина Адама она увеличивается вместе со средней ошибкой, как показано в Таблице 4.
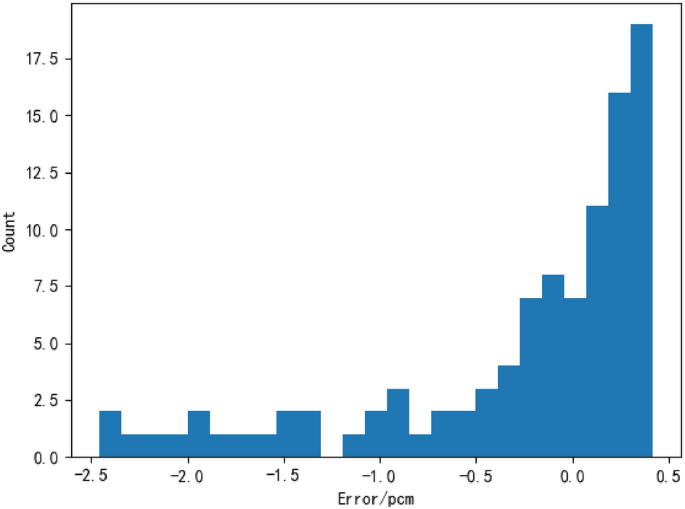
При расчете 1600 моделей в общей сложности 138 моделей имели среднюю ошибку менее 10 пк, и были рассчитаны 10 моделей с наименьшей средней ошибкой, как показано в таблице 5. Модель с наименьшей средней ошибкой (т.е. временной шаг 3) , номер ячейки 16, коэффициент регуляризации 0,003 и выбор, оптимизированный по Adadelta), отображают статистику ошибок, а статистические результаты показаны на рисунке 8.

«Главный евангелист пива. Первопроходец в области кофе на протяжении всей жизни. Сертифицированный защитник Твиттера. Интернетоголик. Практикующий путешественник».
More Stories
Развитие рака кожи, его профилактики и лечения за последний год
Скручивание и связывание волн материи с фотонами в полости
Старый космический телескоп «Хаббл» возвращается к жизни после неисправности